华三H3C交换机在三层配置IRF堆叠和MAD配置。
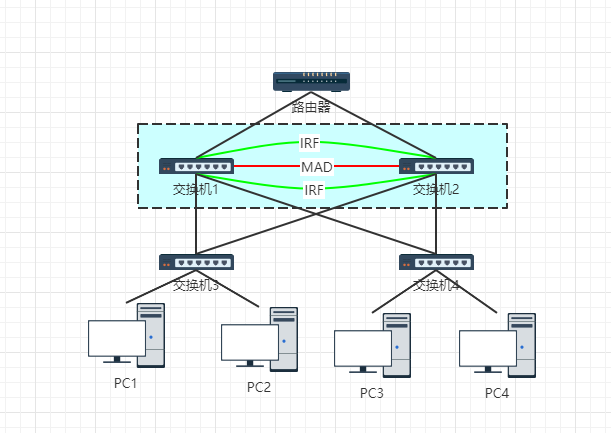
一、网络拓扑
交换机1和交换机2处于局域网的三层,为了提高性能和稳定性使用了IRF堆叠。
二、IRF堆叠
1、交换机1配置
交换机1修改priority(值范围1-32),priority值越大优先级越高,优先级最高的会成为Master
华三H3C交换机在三层配置IRF堆叠和MAD配置。
一、网络拓扑
交换机1和交换机2处于局域网的三层,为了提高性能和稳定性使用了IRF堆叠。
二、IRF堆叠
1、交换机1配置
交换机1修改priority(值范围1-32),priority值越大优先级越高,优先级最高的会成为Master
SAP客户端GUI有默认的系统风格,升级版本后默认风格也可能会变更,导致用起来不习惯。
本教程以SAP GUI 770为例:
一、主题风格设置
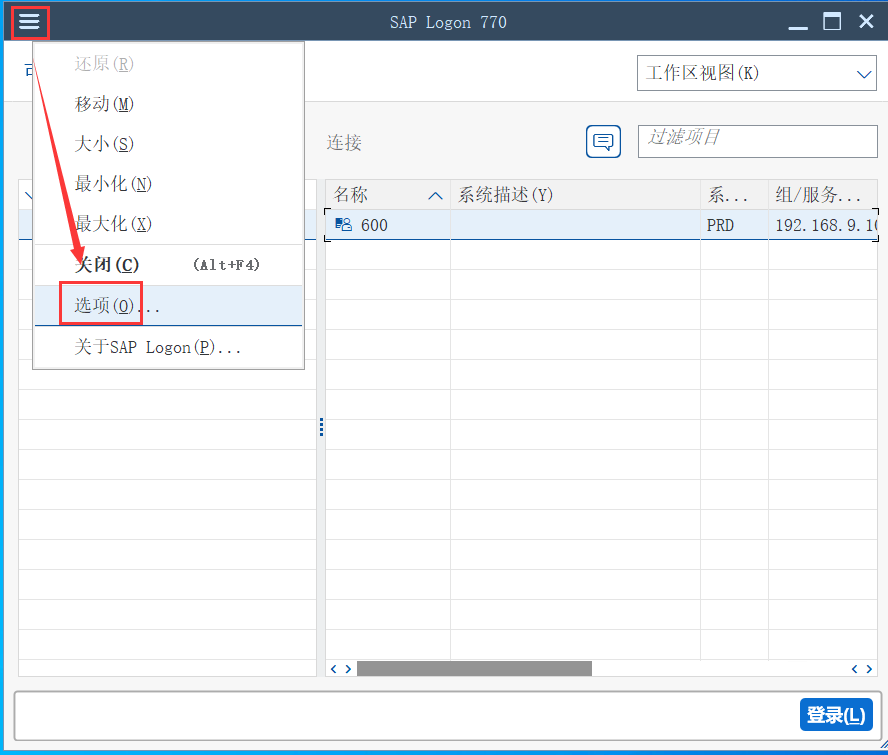
1、打开SAP GUI,点击GUI左上角的菜单,然后点击”选项“
因为审批链在SAP,所以对于SAP需要有邮件提醒。
以下是SAP发送邮件的SMTP配置教程:
一、SMTP端口参数配置
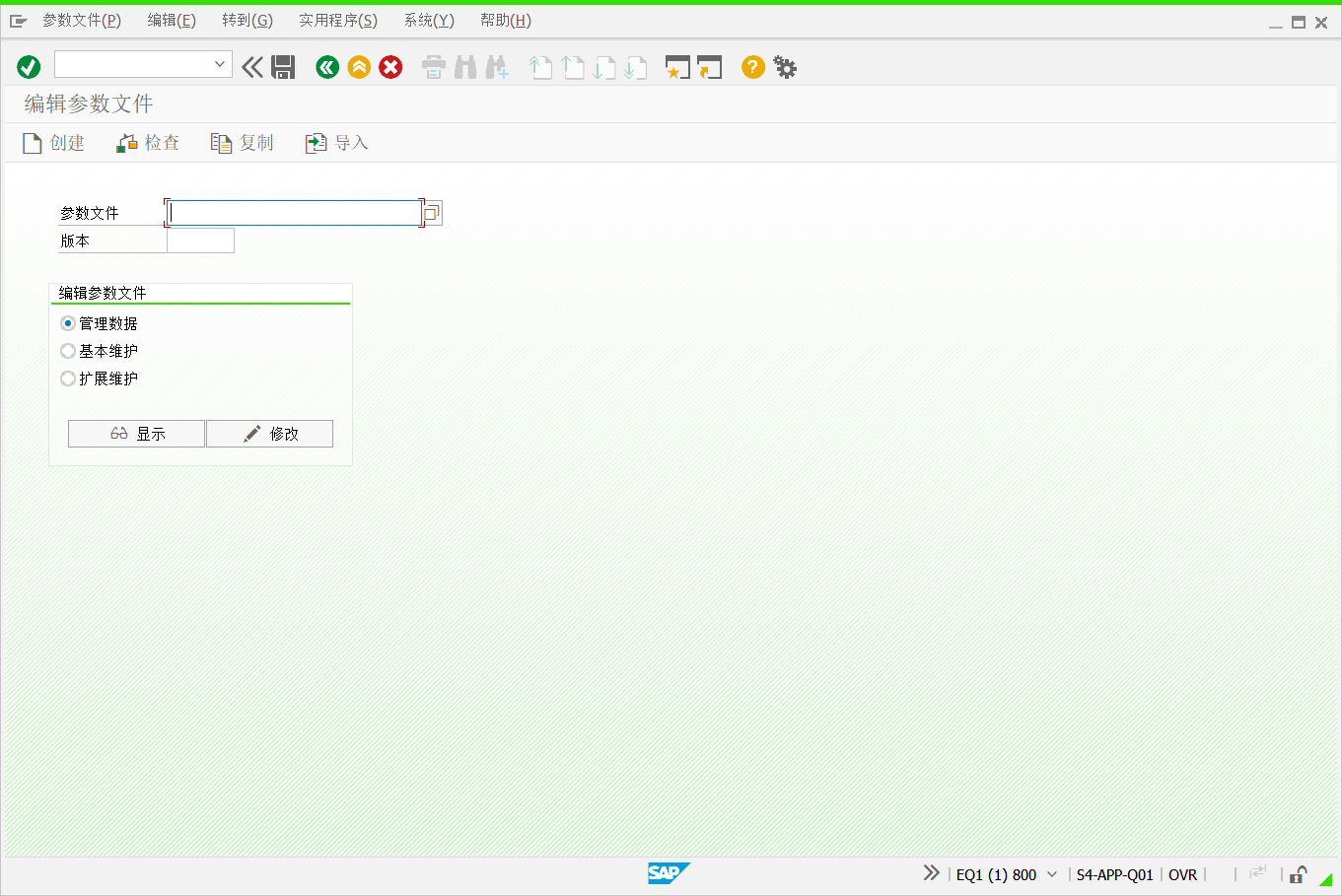
1、输入T-CODE:RZ10,参数文件:DEFAULT,版本选择最新的版本,选择扩展维护,点击修改
SAP的创建用户并分配权限的操作教程。
一、事务码SU01:创建用户
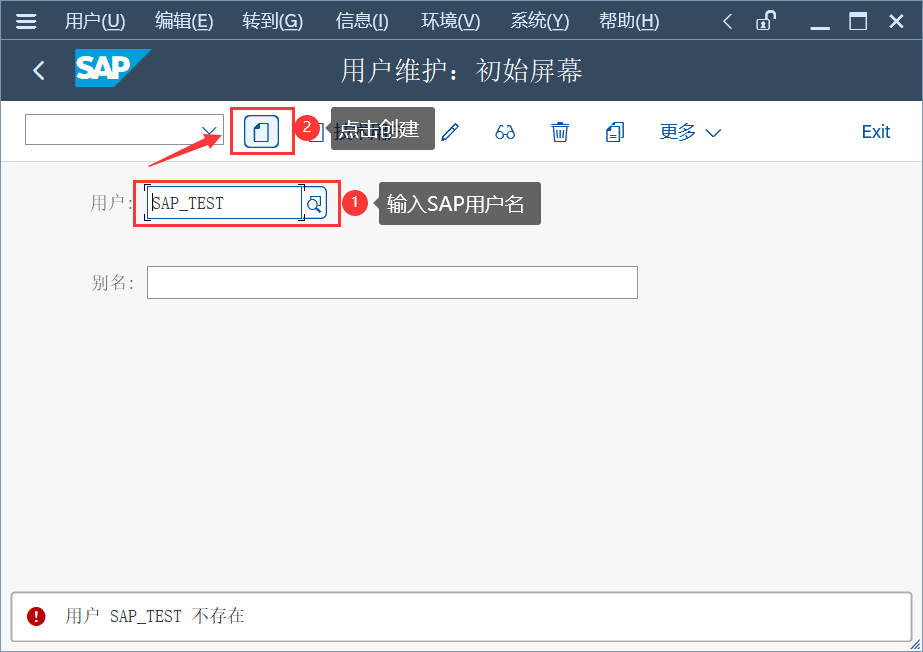
事务码:SU01 进行创建用户,也可以进行复制创建(包含编辑)
1、用户输入新用户名,回车后,点击创建按钮
ATOM编辑器是一款免费的开源软件,支持 Windows、Mac、Linux 桌面平台,还支持外置插件,并且已经在 GitHub 上开放了全部的源代码。
一、ATOM换源
Atom的插件在npm上,而npm的官方源在国内访问起来是非常缓慢的(国内特色),所以这个时候考虑到换成国内源。如淘宝源(http://registry.npm.taobao.org/)和CNPM(http://r.cnpmjs.org)。
1、apm命令法
使用命令:apm config set registry npm_mirror_url
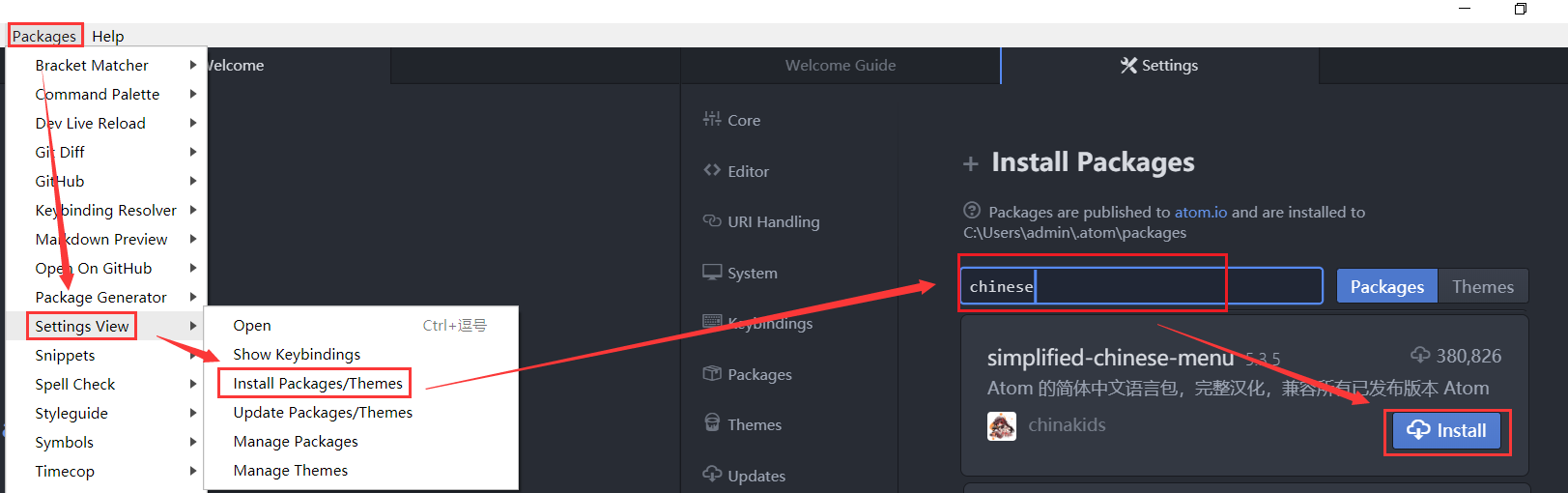
问题描述
在Windows7/Windows 8/windows10下安装Office 2013,出现错误1921或者1920。
错误1920。未能启动服务“Windows Font Cache Service”(FontCache)。请确定您有足够的权限启动系统服务。
错误1921。无法停止服务“Windows Font Cache Service”(FontCache)。请确定您有足够的权限停止系统服务。
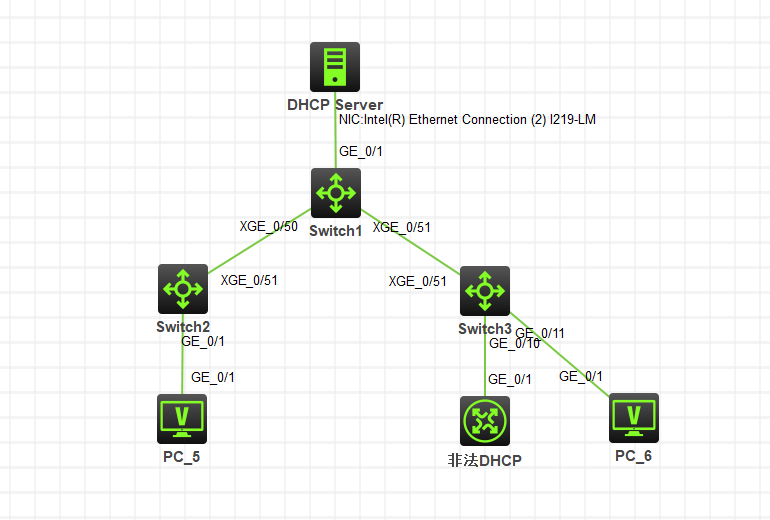
由于 DHCP 协议是二层的,无法找到网络中那台非法 DHCP 服务器的源、目的 IP 地址。如果网络里面同时有多台 DHCP 服务器,而你的交换机没有阻止 DHCP 协议的发布,那么这种情况很容易造成无法上网的问题。
一、环境模拟
如以下图示3台交换机,交换机1接正常的DHCP服务器(10.0.0.X),但是交换机3被接入了1台非法的DHCP服务器(192.168.10.X),那么PC_5或PC_6很容易接入到非法的DHCP服务中去。所以需要在接入层交换机上开启DHCP SNOOPING功能,用来防止非法DHCP。
ZXA10 F460中兴光猫(E8-C),在第一次安装的时候,超级管理员帐号:telecomadmin 密码:nE7jA%5m 这个是默认的,由安装人员设置好相关设置后,会自动下载配置,这个时候这个超级管理员密码会被修改,修改为telecomadminXXXXXXXX(8个X是8位数字,每个用户是不同的)这种格式。因为很多设置需要在超级管理员下才能设置,所以破解这个超级管理员密码是非常必要的。
破解方法
方法1:打10000号,报设备号可以查到。(当然最好让安装人员打电话去查),我这里是苏州电信,我自己打的10000,说了很久…………可以查到。这个方法最简单,也最没有危险。
PS:跟安装工程师套套近乎,要到他们的电话,他们可以跟服务台联系报出光猫的设备号算出超级密码的。
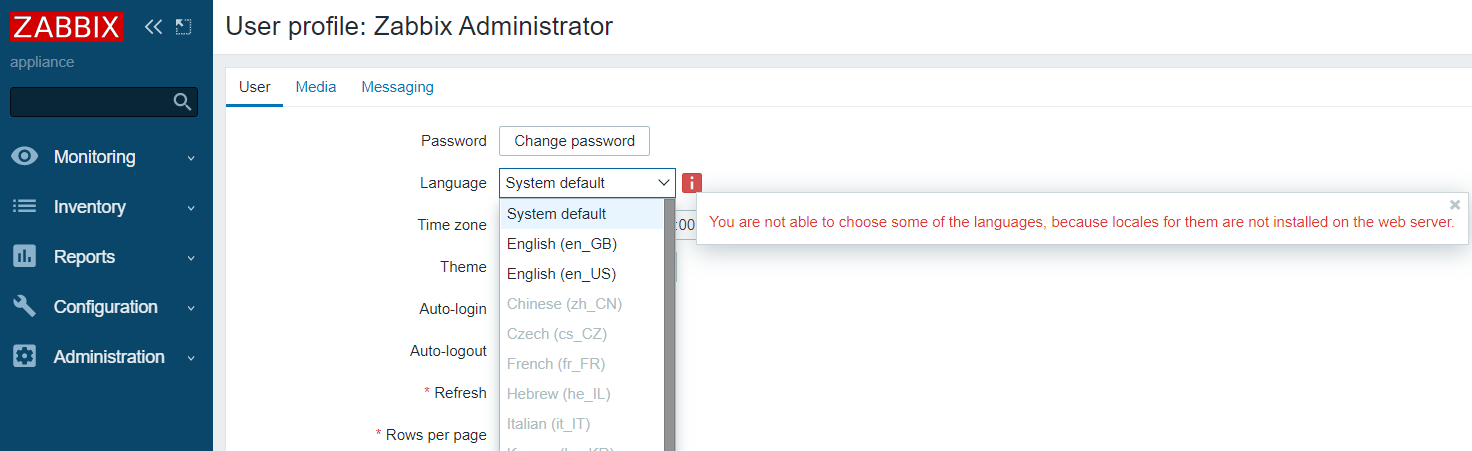
问题描述
通过Zabbix Web后台无法选择中文语言包,提示”You are not able to choose some of the languages, because locales for them are not installed on the web server.“
解决方法
1、通过命令安装中文语言包,SSH连接到zabbix,这边使用的是虚拟化版本,账号是root密码是zabbix。
[root@appliance ~]# dnf install langpacks-zh_CN.noarch
2、刷新Zabbix Web后台,这个时候可以选择简体中文,点一下更新即可
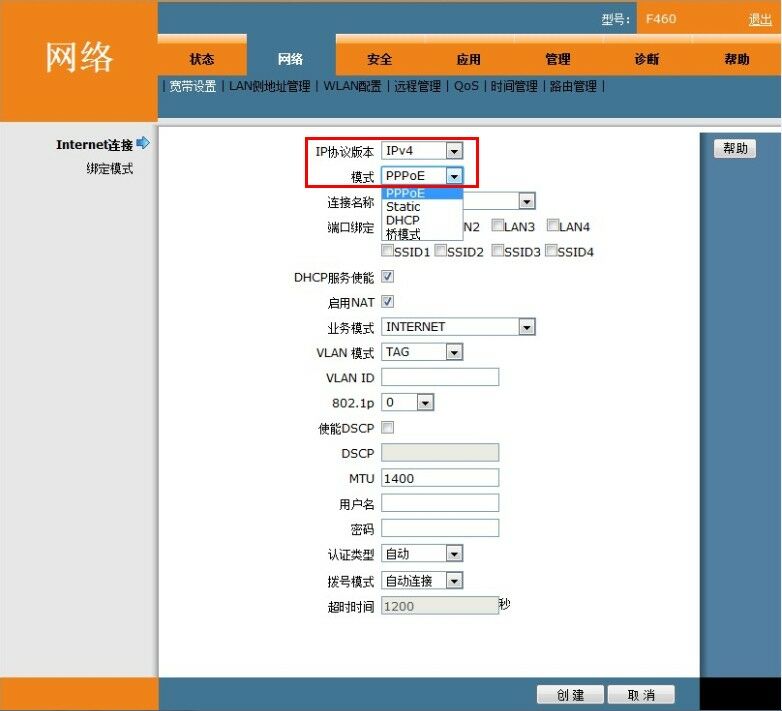
电信的光猫,我这里用中兴F460演示,其实电信的光猫桥接和路由模式设置多是差不多的,就连我以前的ADSL华为猫和光猫的这个设置差不多多少了。
由于光猫的硬件配置有好有差,带宽各个地方也是不同,对于桥接来说,速度几乎没有影响。而路由模式下,由于光猫配置差,电信开的带宽也比较大,造成路由模式下光猫处理不过来,速度影响也就比较大。
看使用什么模式就看自己的需要,有条件能用自己的路由器的尽量使用自己的无线路由器,路由模式下光猫发热量大,信号不好,有数量限制(这个可以破解)。
那么说说光猫,我这里的光猫设置的初始模式,LAN1,3,4,SSID1全是桥接,可以用来拨号上网。而LAN2和SSID2也是桥接,但是是ITV的接口。2个区别在VLAN和一部分的设置。如果有自己的路由器,直接用在LAN1,3,4上,通过路由器的PPPoE拨号上网就可以了,不用破解光猫。
现在主要来说说,如何使用光猫的多种模式。





